
Run and observe the agent
- Build the toolkit
- Define agent behavior
- Workflow & Worker
- Run and observe
You now have everything in place to run your agent. In this final chapter you'll build a FastAPI backend so a UI can interact with the Workflow, run the agent end to end, trace its execution in the Temporal Web UI, and witness Temporal's durability across simulated failures.
Building a REST API for interacting with your agent
Now that you have your agent implemented, you need a way for client applications to interact with it. Temporal provides client libraries, but having an API to manage invoking a Workflow, sending Signals and Queries, and managing various Workflow Executions is a typical pattern for managing Temporal Workflows.
In this step, you will create a backend API that will serve as the interface for interacting with your agent. You'll use the FastAPI framework to build this. FastAPI is a great choice to pair with Temporal, as it's an async Python backend that supports type hints.
Setting up the FastAPI application
First, create the directory structure for your FastAPI application:
mkdir api
Next, create the API file at api/main.py and include the following import statements:
import asyncio
from collections import deque
from contextlib import asynccontextmanager
from typing import Dict, Optional
from dotenv import load_dotenv
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from temporalio.api.enums.v1 import WorkflowExecutionStatus
from temporalio.client import Client
from temporalio.exceptions import TemporalError
from models.requests import AgentGoalWorkflowParams, CombinedInput, ConversationHistory
from shared.config import TEMPORAL_TASK_QUEUE, get_temporal_client
from tools.goal_registry import goal_event_flight_invoice
from workflows.agent_goal_workflow import AgentGoalWorkflow
This imports various packages from the standard library, third-party libraries including FastAPI and Temporal, and a few of your custom libraries. The API imported the AgentGoalWorkflow so it can invoke it, the goal_event_flight_invoice for specification of the goal, the get_temporal_client function and TEMPORAL_TASK_QUEUE constant for communicating with the Temporal service, and a few of your custom types for proper communication with the Workflow.
Next, add the code to configure and instantiate the FastAPI object:
temporal_client: Optional[Client] = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global temporal_client
# Create the Temporal client
temporal_client = await get_temporal_client()
yield
app = FastAPI(lifespan=lifespan)
# Load environment variables
load_dotenv()
AGENT_GOAL = goal_event_flight_invoice
This creates a Temporal client, then uses the lifespan function to call the get_temporal_client function. The lifespan function, paired with the @asynccontextmanager decorator defines a context manager that defines startup and shutdown behavior for your FastAPI app. Next, it creates the FastAPI app, passing in the lifespan as a parameter. Finally, you load in the environment variables and specify the AGENT_GOAL to goal_event_flight_invoice.
Next, add the appropriate middleware for handling CORS and define the root handler for your app:
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:5173"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/")
def root() -> Dict[str, str]:
return {"message": "Temporal AI Agent!"}
The CORS settings are set up to allow for access from an origin. Any request to the root of your application will return JSON with a single key and a message.
Before moving on, test your FastAPI app by running the following commands:
In one terminal, start your Temporal development server:
temporal server start-dev
This starts a local Temporal service running on port 7233 with the web UI running on port 8233. The output of this command should resemble (the exact version numbers may not match):
CLI 1.1.1 (Server 1.25.1, UI 2.31.2)
Server: localhost:7233
UI: http://localhost:8233
Metrics: http://localhost:53697/metrics
In another terminal, start the API using uv from the root of your project:
uv run uvicorn api.main:app --reload
This uses uvicorn, an ASGI server to run the FastAPI app and auto reload the app if any changes are detected.
The output of this command should resemble:
INFO: Will watch for changes in these directories: ['/Users/ziggy/temporal-ai-agent']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [31826] using StatReload
INFO: Started server process [31828]
INFO: Waiting for application startup.
Address: localhost:7233, Namespace default
(If unset, then will try to connect to local server)
INFO: Application startup complete.
Next, test your application is working by sending a request to it:
curl localhost:8000
Your response should be:
{"message":"Temporal AI Agent!"}
Now that you have the base FastAPI application configured with a Temporal client, you will implement the functions to interact with your agent Workflow.
Implementing agent Workflow endpoints
Your API only needs a few endpoints to communicate with the agent. You will implement the functionality to send Signals, get the conversation history, and start the Workflow.
Validating the Temporal client
Every function will use the same Temporal client. First, you will implement a helper function to verify the client is set up correctly.
Add the following function to your main.py file:
def _ensure_temporal_client() -> Client:
"""Ensure temporal client is initialized and return it.
Returns:
TemporalClient: The initialized temporal client.
Raises:
HTTPException: If client is not initialized.
"""
if temporal_client is None:
raise HTTPException(status_code=500, detail="Temporal client not initialized")
return temporal_client
This function ensures the global Temporal client is not None. If it isn't, the function returns the client. If it is None, it will raise an exception. This is a type-safe way of validating the client before every function call.
Starting the agent Workflow
Next, you'll define an endpoint that a client will use to start the agent Workflow. This endpoint is a POST endpoint, and doesn't take any parameters.
Add the endpoint to your api.py file:
@app.post("/start-workflow")
async def start_workflow() -> Dict[str, str]:
"""Start the AgentGoalWorkflow"""
temporal_client = _ensure_temporal_client()
# Create combined input
combined_input = CombinedInput(
tool_params=AgentGoalWorkflowParams(
None, deque([f"### {AGENT_GOAL.starter_prompt}"])
),
agent_goal=AGENT_GOAL,
)
workflow_id = "agent-workflow"
# Start the workflow with the starter prompt from the goal
await temporal_client.start_workflow(
AgentGoalWorkflow.run,
combined_input,
id=workflow_id,
task_queue=TEMPORAL_TASK_QUEUE,
)
return {
"message": f"Workflow started with goal's starter prompt: {AGENT_GOAL.starter_prompt}."
}
The code verifies the Temporal client, then creates a CombinedInput type containing an AgentGoalWorkflowParams object and the AGENT_GOAL. The AgentGoalWorkflowParams object assigns None to its first attribute, which represents the conversation history. This is fine, as there is currently no conversation history. The second attribute is the first prompt the agent will execute. You then specify the workflow_id that will identify the execution, in this case it is hard coded to agent-workflow. Finally, you start the Workflow asynchronously using temporal.client.start_workflow, specifying the Workflow method AgentGoalWorkflow.run, the parameter combined_input, workflow_id, and task_queue.
The function then returns with a message stating that the Workflow has started.
Sending a user prompt to the Workflow
Now you'll implement sending the user's prompt to the Workflow. The user will interact with the chatbot interface, sending messages to the agent. The chatbot sends these as Signals to the user_prompt Signal handler you defined in your Workflow.
Add the following code to send the user's prompt to the Workflow:
@app.post("/send-prompt")
async def send_prompt(prompt: str) -> Dict[str, str]:
"""Sends the user prompt to the Workflow"""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("user_prompt", prompt)
return {"message": f"Prompt '{prompt}' sent to workflow {workflow_id}."}
This code identifies the Workflow Execution by its workflow_id, and sends the user's prompts sent to the API as Signals to that Workflow Execution.
Sending a confirmation to the Workflow
If you have the SHOW_CONFIRM option set in your .env file, then the user must confirm the tool before it is executed. This choice is sent to the workflow via a Signal. You already implemented the Signal handler in the Workflow, now you will implement sending the Signal.
Add the following code to send the confirm Signal:
@app.post("/confirm")
async def send_confirm() -> Dict[str, str]:
"""Sends a 'confirm' signal to the workflow."""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("confirm")
return {"message": "Confirm signal sent."}
This code identifies the Workflow Execution by its workflow_id, and sends the Signals sent to the API to that Workflow Execution.
Ending the chat
Finally, the user can choose to end the chat at any time by saying something along the lines of "end conversation." You also implemented this Signal handler in your Workflow, so now you'll implement the sending of the Signal.
Add the following code:
@app.post("/end-chat")
async def end_chat() -> Dict[str, str]:
"""Sends a 'end_chat' signal to the workflow."""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("end_chat")
return {"message": "End chat signal sent."}
This code identifies the Workflow Execution by its workflow_id, and sends the Signals sent to the API to that Workflow Execution.
Retrieving the conversation history
The last API endpoint you must implement retrieves the conversation history. The UI uses this to populate the interface for the user to read. This API will perform a Query and retrieve the information from the running Workflow Execution.
Add the following code to implement the endpoint:
@app.get("/get-conversation-history")
async def get_conversation_history() -> ConversationHistory:
"""Calls the workflow's 'get_conversation_history' query."""
temporal_client = _ensure_temporal_client()
try:
handle = temporal_client.get_workflow_handle("agent-workflow")
failed_states = [
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_TERMINATED,
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_CANCELED,
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_FAILED,
]
description = await handle.describe()
if description.status in failed_states:
print("Workflow is in a failed state. Returning empty history.")
return []
# Set a timeout for the query
try:
conversation_history = await asyncio.wait_for(
handle.query("get_conversation_history"),
timeout=5, # Timeout after 5 seconds
)
return conversation_history
except asyncio.TimeoutError:
raise HTTPException(
status_code=404,
detail="Temporal query timed out (worker may be unavailable).",
)
except TemporalError as e:
error_message = str(e)
print(f"Temporal error: {error_message}")
# If worker is down or no poller is available, return a 404
if "no poller seen for task queue recently" in error_message:
raise HTTPException(
status_code=404, detail="Workflow worker unavailable or not found."
)
if "workflow not found" in error_message:
await start_workflow()
return []
else:
# For other Temporal errors, return a 500
raise HTTPException(
status_code=500, detail="Internal server error while querying workflow."
)
This function identifies the Workflow by its Workflow ID, then checks the Workflow Execution's status, making sure it isn't in a failed state. It then performs the Query, setting a timeout of five seconds, handling various errors as they may occur. If the Workflow Execution isn't found however, the endpoint will actually kick it off.
The api/main.py is complete and will need no more revisions. You can review the complete file and copy the code here.
import asyncio
from collections import deque
from contextlib import asynccontextmanager
from typing import Dict, Optional
from dotenv import load_dotenv
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from temporalio.api.enums.v1 import WorkflowExecutionStatus
from temporalio.client import Client
from temporalio.exceptions import TemporalError
from models.requests import AgentGoalWorkflowParams, CombinedInput, ConversationHistory
from shared.config import TEMPORAL_TASK_QUEUE, get_temporal_client
from tools.goal_registry import goal_event_flight_invoice
from workflows.agent_goal_workflow import AgentGoalWorkflow
temporal_client: Optional[Client] = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global temporal_client
# Create the Temporal client
temporal_client = await get_temporal_client()
yield
app = FastAPI(lifespan=lifespan)
# Load environment variables
load_dotenv()
AGENT_GOAL = goal_event_flight_invoice
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:5173"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/")
def root() -> Dict[str, str]:
return {"message": "Temporal AI Agent!"}
def _ensure_temporal_client() -> Client:
"""Ensure temporal client is initialized and return it.
Returns:
TemporalClient: The initialized temporal client.
Raises:
HTTPException: If client is not initialized.
"""
if temporal_client is None:
raise HTTPException(status_code=500, detail="Temporal client not initialized")
return temporal_client
@app.post("/start-workflow")
async def start_workflow() -> Dict[str, str]:
"""Start the AgentGoalWorkflow"""
temporal_client = _ensure_temporal_client()
# Create combined input
combined_input = CombinedInput(
tool_params=AgentGoalWorkflowParams(
None, deque([f"### {AGENT_GOAL.starter_prompt}"])
),
agent_goal=AGENT_GOAL,
)
workflow_id = "agent-workflow"
# Start the workflow with the starter prompt from the goal
await temporal_client.start_workflow(
AgentGoalWorkflow.run,
combined_input,
id=workflow_id,
task_queue=TEMPORAL_TASK_QUEUE,
)
return {
"message": f"Workflow started with goal's starter prompt: {AGENT_GOAL.starter_prompt}."
}
@app.post("/send-prompt")
async def send_prompt(prompt: str) -> Dict[str, str]:
"""Sends the user prompt to the Workflow"""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("user_prompt", prompt)
return {"message": f"Prompt '{prompt}' sent to workflow {workflow_id}."}
@app.post("/confirm")
async def send_confirm() -> Dict[str, str]:
"""Sends a 'confirm' signal to the workflow."""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("confirm")
return {"message": "Confirm signal sent."}
@app.post("/end-chat")
async def end_chat() -> Dict[str, str]:
"""Sends a 'end_chat' signal to the workflow."""
temporal_client = _ensure_temporal_client()
workflow_id = "agent-workflow"
handle = temporal_client.get_workflow_handle(workflow_id)
await handle.signal("end_chat")
return {"message": "End chat signal sent."}
@app.get("/get-conversation-history")
async def get_conversation_history() -> ConversationHistory:
"""Calls the workflow's 'get_conversation_history' query."""
temporal_client = _ensure_temporal_client()
try:
handle = temporal_client.get_workflow_handle("agent-workflow")
failed_states = [
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_TERMINATED,
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_CANCELED,
WorkflowExecutionStatus.WORKFLOW_EXECUTION_STATUS_FAILED,
]
description = await handle.describe()
if description.status in failed_states:
print("Workflow is in a failed state. Returning empty history.")
return []
# Set a timeout for the query
try:
conversation_history = await asyncio.wait_for(
handle.query("get_conversation_history"),
timeout=5, # Timeout after 5 seconds
)
return conversation_history
except asyncio.TimeoutError:
raise HTTPException(
status_code=404,
detail="Temporal query timed out (worker may be unavailable).",
)
except TemporalError as e:
error_message = str(e)
print(f"Temporal error: {error_message}")
# If worker is down or no poller is available, return a 404
if "no poller seen for task queue recently" in error_message:
raise HTTPException(
status_code=404, detail="Workflow worker unavailable or not found."
)
if "workflow not found" in error_message:
await start_workflow()
return []
else:
# For other Temporal errors, return a 500
raise HTTPException(
status_code=500, detail="Internal server error while querying workflow."
)
You just implemented an API allowing client programs to interact with your agent.
Before moving on to the next section, verify your files and directory structure is correct.
temporal-ai-agent/
├── .env
├── .gitignore
├── .python-version
├── README.md
├── pyproject.toml
├── uv.lock
├── activities/
| ├── __init__.py
| └── activities.py
├── api/
│ └── main.py
├── models/
│ ├── __init__.py
│ ├── core.py
│ └── requests.py
├── prompts/
│ ├── __init__.py
│ ├── agent_prompt_generators.py
│ └── prompts.py
├── scripts/
│ ├── create_invoice_test.py
│ ├── find_events_test.py
│ └── search_flights_test.py
├── tools/
│ ├── __init__.py
│ ├── create_invoice.py
│ ├── find_events.py
│ ├── goal_registry.py
│ ├── search_flights.py
│ ├── tool_registry.py
│ └── data/
| └── find_events_data.json
├── worker/
│ └── worker.py
└── workflows/
├── __init__.py
├── agent_goal_workflow.py
└── workflow_helpers.py
In the next step, you will test your agent using a chatbot web interface.
Running your agent
Now that you have implemented a mechanism of communication for your agent, it's time to test it. You will now download a React frontend that implements a chatbot UI to interact with your agent. The UI will open in a terminal window and prompt the user with a message stating their purpose and instructing the user what to do next. Throughout the conversation, the user will interact with the agent, responding to questions from the agent as the agent tries to accomplish its goal.
Adding a Chatbot Web UI
To get started, download the pre-built React based web UI:
curl -o frontend.zip https://raw.githubusercontent.com/temporal-community/tutorial-temporal-ai-agent/main/frontend.zip
Once downloaded, extract the files from the zip to your root directory. You can do this with your OS's tool, or with a command line tool like unzip:
unzip frontend.zip
Next, change directories into the frontend directory that was just extracted and install the packages to run the UI:
cd frontend
npm install
Once the packages are finished installing, the web UI is ready to interact with your API.
Starting Your Agent
You now have assembled all the pieces to run the agent to completion. Running the agent requires a minimum of four different terminals, however there will only be one Worker process running. You can either open multiple terminals, or use a terminal multiplexer like screen or tmux. This tutorial can function with a single Worker. However, as with all real-world Temporal deployments, it is always better to run multiple Workers for scaling and redundancy.
The first requirement is running a local Temporal server that coordinates workflow execution and provides durability guarantees.
In the first terminal, start the development server:
temporal server start-dev
This starts a local Temporal service running on port 7233 with the web UI running on port 8233. The output of this command should resemble (the exact version numbers may not match):
CLI 1.1.1 (Server 1.25.1, UI 2.31.2)
Server: localhost:7233
UI: http://localhost:8233
Metrics: http://localhost:53697/metrics
In the second terminal, start your Worker:
uv run worker/worker.py
You should see the following output:
Worker will use LLM model: openai/gpt-4o
Address: localhost:7233, Namespace default
(If unset, then will try to connect to local server)
AgentActivities initialized with LLM model: openai/gpt-4o
Worker ready to process tasks!
Starting worker, connecting to task queue: agent-task-queue
Ready to begin processing...
If you are able, running a second Worker in another terminal is recommended using the steps above.
Next, open another terminal and run the FastAPI application:
uv run uvicorn api.main:app --reload
This uses uvicorn, an ASGI server to run the FastAPI app and auto-reload the app if any changes are detected.
The output of this command should resemble:
INFO: Will watch for changes in these directories: ['/Users/ziggy/temporal-ai-agent']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [31826] using StatReload
INFO: Started server process [31828]
INFO: Waiting for application startup.
Address: localhost:7233, Namespace default
(If unset, then will try to connect to local server)
INFO: Application startup complete.
Finally, open the last new terminal, change directories into the frontend directory and start the web UI:
cd frontend
npx vite
You will see output to your terminal, and then your web browser will open to localhost:5173 with your agent running.
When first starting the web UI, you may see a red error banner appear upon startup with a message about timeouts. This is expected, as the UI begins polling immediately before the Workflow may begin. This will go away within a few seconds once the Workflow Execution has started and the first message from the agent appears.
Finally, open a new browser tab and navigate to localhost:8233. This will display the Temporal Web UI. You should see a running Workflow Execution there with the Workflow ID agent-workflow. Click on the link to open it so you can watch the Workflow progress as you test your agent.
Testing the complete system
With all components running, you can now test the agent Workflow.
Navigate back to localhost:5173. You should see a message similar to the following. Remember, the agent's responses are powered by an LLM, so the responses are non-deterministic, meaning they are likely to be slightly different every time.
Agent: Welcome! I'm here to help you plan your travel to events in North America.
I can assist you in finding events, booking flights, and generating invoices for your trip.
To get started, please tell me which city and month you're interested in traveling to?
Test the conversation by responding with a city you'd like to travel to and the month you want to travel:
You: I'd like to see events in San Francisco in March
The agent will process receive your prompt and use the LLM to determine the next step:
Agent: Let's proceed with finding events in San Francisco in March.
It will determine that it should use the FindEvents tool and search for events.
If you have the SHOW_CONFIRM environment variable set to True, the UI will prompt you to confirm execution of this tool and all future tool executions. By default this is enabled, so you will need to confirm the execution.
Once you have confirmed the tool execution, the agent executes the tool and provides events for you to choose from:
Agent: I found a couple of events in San Francisco:
1. Lunar New Year Festival & Parade from February 8 to February 22, 2026
2. San Francisco International Film Festival from April 17 to May 1, 2026
Would you like to search for flights to attend any of these events? If so, please provide your departure city.
You can then respond with which event you'd like to attend:
You: I would like to attend the San Francisco International Film Festival
However, you forgot to provide the departure city here, which the agent recognized and then prompted you for again.
Agent: Great choice! The San Francisco International Film Festival is from April 17 to May 1, 2026.
Please provide your departure city so I can search for flights.
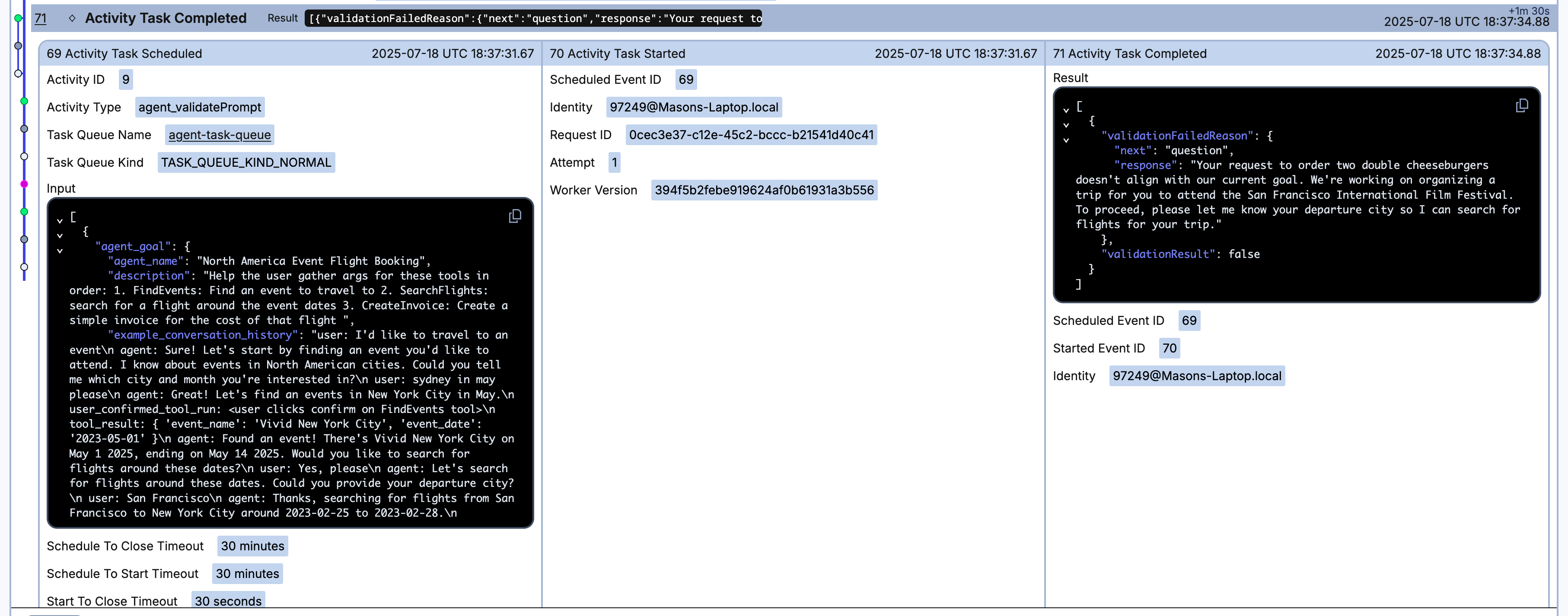
Thinking about lunch, you accidentally input your lunch order into the chatbot:
I would like to order two double cheeseburgers.
The agent's guardrails recognize this isn't valid for its goal, so it informs you and prompts you to enter your departure city.
Agent: Your request to order two double cheeseburgers doesn't align with our current goal.
We're working on organizing a trip for you to attend the San Francisco International Film Festival.
To proceed, please let me know your departure city so I can search for flights for your trip.
You then provide it with your departure city:
You: I'm sorry. I'd like to depart from Austin, TX
The agent now has the information it needs, and can move on to the next step. However, it may decide to confirm with you again to ensure that's what you meant.
Agent: Thanks! You're departing from Austin, TX.
Would you like to proceed with searching for flights from Austin to San Francisco for the San Francisco International Film Festival?
To which you should either confirm or deny. In this instance, confirm:
You: Yes
This extra confirmation step may not always happen. It depends if the LLM decides to verify.
However, it is now satisfied and is ready to execute the next tool. This is evident because after this response, you are asked to confirm execution for the SearchFlights tool:
Agent: Let's proceed with searching for flights from Austin, TX (AUS) to San Francisco (SFO) around the dates of April 17 to May 1, 2026.
After you confirm the tool usage, the agent then executes the tool, searching for flights to your destination.
If you have supplied a RAPIDAPI key, this will make a call to a microservice to check for real flight data. If the API returns multiple times with an error or no flights, this is the external API being unreliable and returning sporadic error messages. To alleviate this, use the mocked function instead.
Once the agent finds flight options, it will present them to you, allowing you to select a flight if there are multiple. It will prompt you if you would like to create an invoice for the flight:
Agent:
I found the cheapest flight with Southwest Airlines for $149.75.
Would you like to create an invoice for this flight?
To which you confirm:
You: Yes
And the agent will proceed with creating an invoice, prompting the user to allow the execution of the CreateInvoice tool:
Agent: Let's proceed with creating an invoice for the Southwest Airlines flight.
The agent then creates the invoice, the goal is complete, and the chat is over.
Agent: Invoice generated successfully!
You can view and pay your invoice at: https://pay.example.com/invoice/12345.
Your reference number is INV-12345. If you need further assistance, feel free to ask.
If you set a STRIPE_API_KEY environment variable in your .env file, the tool will use the Stripe API to create an invoice in your Stripe environment. Otherwise, it will create a pseudo link.
Now that the chat is over, the Workflow Execution is over. You can start another chat session by clicking the Start New Chat button in the web UI, which will start a new Workflow Execution.
Next, you'll examine the Event History of your most recent chat session.
Tracing the Workflow Execution in the Web UI
One of the features of Temporal is the observability that you gain via the Temporal Web UI. This is made possible since every event is stored, along with the inputs and output of Workflows, Activities, and other Temporal operations.
Open the Temporal Web UI at http://localhost:8233 and navigate to your most recent run.
Your UI may not look exactly like the screenshots below due to differing UI versions, varying output from LLMs, and different user inputs. This is fine; the core concepts are still applicable.
Navigate to the Workflows page to see your past agent Workflow Executions. This is also the default landing page.
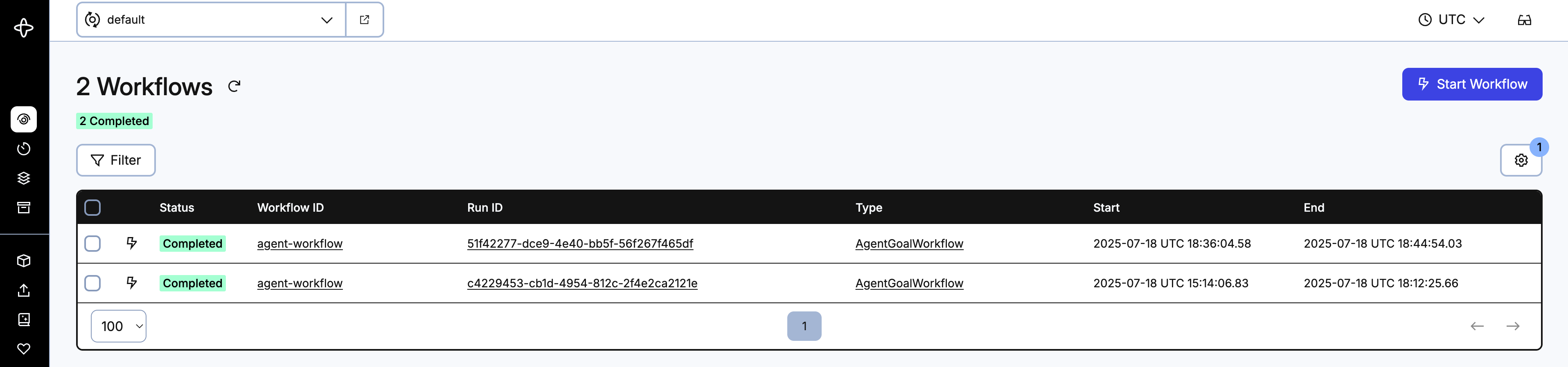
You will see all of your completed and currently running chat sessions here. Click on the Workflow ID link agent-workflow of the most recently completed execution to see the details about that specific execution.
At the top, you'll see the summary for the Workflow Execution. This contains information such as the duration of the execution, when it started, when it ended, what Task Queue it used, the size of the history, and the Workflow Type. All of this information can also be pieced together throughout the Event History, the Summary section provides an easier way to find it.

Next is the Input and Result section. Here you can see the initial input to the Workflow, and the final result that the agent returned in JSON format.
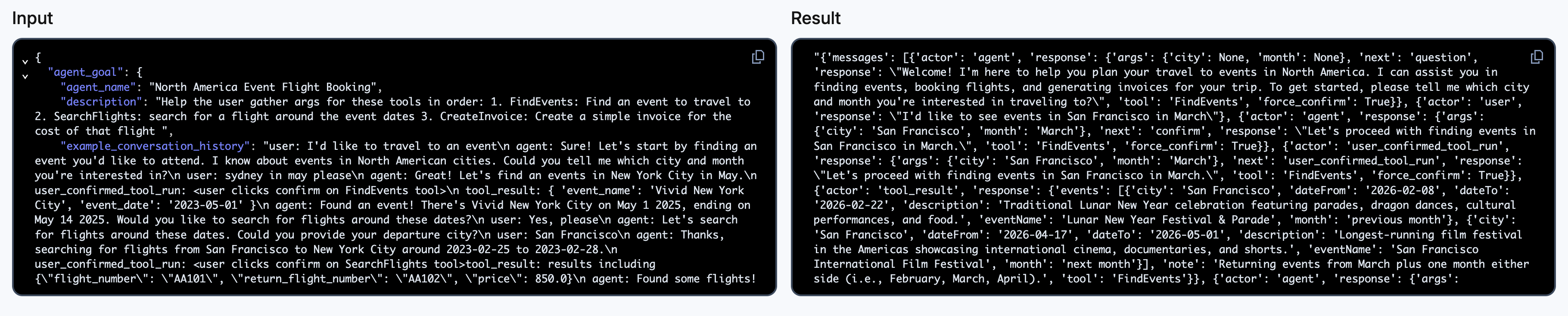
Below that is the Event History timeline. This is a time-based representation of every event that occurred during the execution of the Workflow.

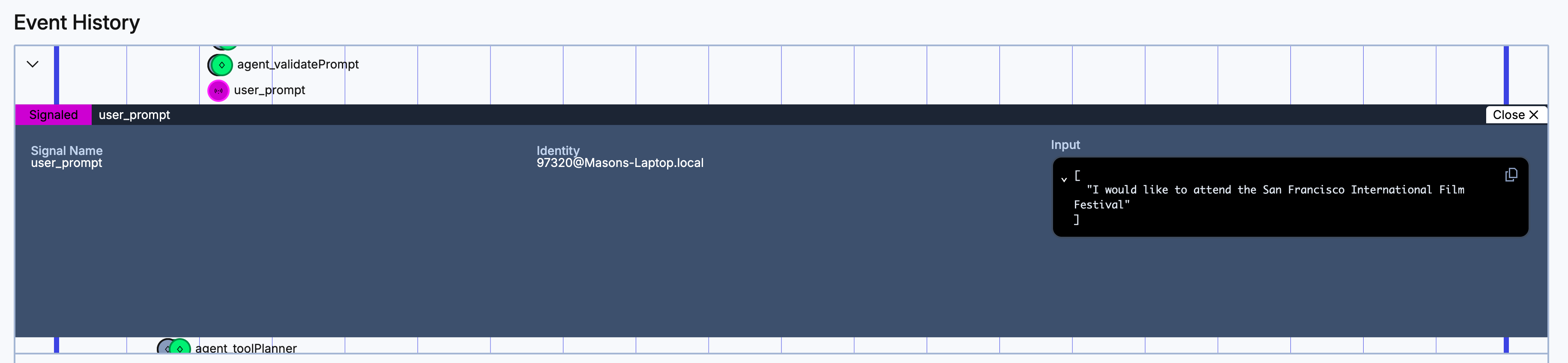
Each individual event in this timeline is expandable. You can click on it and view the details for the event. For example, if you click on a purple Signal icon, you can see the Signal name, the identity of the Worker that processed it, and the input.
Other events will contain other information. Activities will contain information regarding the timeouts, retry policies, and input and results.
Finally, you have the list version of the Event History. Everything that is recorded above is derived from this history. You can click into each individual event and see all the information about a single event. Certain events, such as Activities, that typically come in a group, will be automatically paired for concise viewing as shown below.
You can also use this UI live. During a running Workflow Execution, you can watch live updates as you interact with your chatbot, and see the events come in to the timeline and list views. If you'd like, run another session of your chatbot and have the web UI open in a separate browser tab on another window so you can witness this.
Next, you'll explore a few testing scenarios for demonstrating how Temporal adds durability to your agent.
(Optional) Witnessing the Durability of the Agent
Building your agent with Temporal adds durability to your agent. This means that your agent can withstand failures that traditional applications wouldn't be able to, such as internet outages or process crashes. Perform the following scenarios to witness the durability Temporal provides.
The following scenario is a simulation of one engineer's very bad day at work. Follow along and see how Temporal mitigated potentially outage level issues.
Part 1: Terminating the Worker
Scenario: Your agent is deployed to production. You have a chat session running, and a Worker is processing your Workflow. Suddenly, the virtual machine hosting your Worker is rebooted for updates. The Worker is forcefully terminated and progress appears lost. What happens?
Simulating this scenario:
- Ensure your Temporal development server, Worker (be sure you only have one running), API, and web UI are running.
- Start a new chat session.
- Before typing anything in the chat, kill the Worker using
CTRL-C. - Type a city and month in the chat, and press Send.
- You will see the UI stall, and not make progress. You may also see an error message appear at the top saying Error fetching history.
- Return to the Worker terminal and restart the Worker.
- Return to the web UI and watch for progress. Eventually the message should send and the agent Workflow progresses like nothing happened.
- If you are prompted to confirm the tool execution, do so. Then leave the UI up for the next scenario.
What happened?: When the Worker came back online, it registered with the Task Queue and began listening for tasks it could execute. When the original Worker timed out, not returning a response for the task it was supposed to execute, the new Worker accepted it. The new Worker then rebuilt the state of the original Workflow Execution, up to the point of failure, and continued execution as if nothing happened. This new Worker could have been on another virtual machine within the Worker fleet, or the original Worker when the virtual machine finished its upgrade. This ensured that the state was not lost and the Workflow continued to progress.
Part 2: Turning off the Internet
Scenario: After the upgrade finished, somewhere, miles away, Danny the data center intern trips over an improperly managed power cable and the network switch to the rack where your Worker is hosted goes down. While he scrambles to plug it back in, your Worker is intermittently without network access. What happens?
Simulating this scenario:
- Either continue from the previous session, or start with a new chat window and don't send a message yet.
- Turn off your Wifi/Unplug your network adapter to simulate this failure.
- Respond to the prompt the agent posed to you. The agent will validate this using the LLM, which it won't be able to access.
- Go to your Temporal Web UI at
localhost:8233and find the failing Activity. You will see it attempting to retry the call to the LLM. - Turn the internet back on.
- Eventually, the LLM call will succeed, with no intervention from the developer.
- If you are prompted to confirm the tool execution, do so. Then leave the UI up for the next scenario.
What happened?: Temporal Activities are retried automatically upon failure. Intermittent failures such as network outages are often fixed via retries. Each Activity has a default Retry Policy that retries, then backs off increasingly to a maximum duration. Once the network comes back online, at the next retry interval the LLM call will execute and succeed.
Part 3: Swapping out LLMs
Scenario: Now that the switch is back online, the developer can breathe a sigh of relief. Unfortunately they get paged that their OpenAI credits are depleted, there are angry customers trying to use the chatbot, and the only person with a corporate card to replenish the credits is on PTO. You have an Anthropic account with some Claude credits you can swap in quickly.
This scenario requires an Anthropic account with a Claude API token.
Simulating this scenario:
- Either continue from the previous session, or start with a new chat window. Send a few chats to make progress in the Workflow, but do not complete it.
- Open the
.envfile and modify the following variables:LLM_MODEL:anthropic/claude-sonnet-4-20250514LLM_KEY: Your LLM Key
- Restart the Worker.
- Respond to the next prompt in the chat.
- The agent will respond as if nothing happened, continuing the conversation.
What happened?: Since the agent is durable and preserves state, the conversation history was preserved when the Worker was terminated. The state of the Workflow was reconstructed to the point where the Worker was terminated, and the conversation history was sent to Claude as context when executing the next prompt. The agent continues executing as if nothing happened.
These are just some of the failure scenarios the agent can survive.
Conclusion
In this tutorial, you built a durable AI agent that handles multi-turn conversations, executes tools to achieve a goal, and recovers from failures. You implemented the agent using Temporal primitives, including Workflows, Activities, Signals, Queries, Workers, and Task Queues. You created a REST API to enable client integration with your agent. You tested your agent with a chatbot interface, and witnessed the agent survive various failure scenarios.
Key architectural patterns
Your implementation demonstrates several important patterns for building AI agent systems:
Durability through orchestration: Temporal Workflows provide automatic state persistence, ensuring conversations survive process crashes, network failures, and infrastructure issues. This durability is essential for AI agents that manage long-running, stateful interactions.
Separation of concerns: The architecture cleanly separates orchestration logic (Workflows), external interactions (Activities), tool implementations (Python functions), and user interface (API), making the system maintainable and extensible.
Observability by design: Every execution step is recorded in the Event History, providing visibility into the agent's execution without the need for extra tools.
Extensibility: The tool and goal registry pattern enables adding defining new tools and goals without modifying the core Workflow logic.
Resources for continued learning
To continue your learning on Temporal and its use for AI, check out the following resources:
- Download and run a more feature-rich version of this agent, which is what inspired this tutorial.
- Learn more about Temporal AI Use Cases.
- Explore the Temporal documentation for more Temporal features and best practices.
- Take a Temporal Course and dive deeper into Temporal topics.
- Ask a question in the Temporal community in the #topic-ai channel.
Final thoughts
The foundation you built in this tutorial enables you to build agents to solve nearly any goal. If you're up to it, try writing your own goal and tools and have the agent execute them. Temporal's Durable Execution brings reliability and observability to long-running, distributed systems, which is exactly what AI agents are.
Check back later for the next installment in this tutorial series, where you will continue to add functionality to your agent.
What's next?
Get notified when we launch new educational content
New courses, tutorials, and learning resources - straight to your inbox.